python
语法
文件类型相关
python 是动态类型语言,存在三种文件类型:python file、python unit test 和 python stub
- python file:普通的 Python 脚本文件,用于编写常规的 Python 代码,如业务逻辑、工具脚本、程序主体等
- python unit test:专门用于编写单元测试的文件,通常与测试框架(如
unittest、pytest)配合使用,用于验证代码功能的正确性 - python stub:存根文件(
.pyi),用于类型提示(Type Hints),不包含实际代码逻辑,仅定义函数、类、变量的类型签名
最后一个 python stub可能不太好理解,由于 python 是动态类型语言,写代码时不强制声明变量类型,但在大型项目里,不明确类型会让代码阅读和维护变难,IDE 也不好做智能提示,Python stub 就是专门用来写类型信息的文件,它里面只写函数、变量、类等的类型,没有实际代码逻辑
变量
python 中对象分为可变对象和不可变对象,主要区别体现在 对象的值能否被修改
- 不可变对象:一旦创建,其值就不能被修改。若要修改值,实际上是创建了一个新对象,原对象保持不变。不可变对象有:int、float、str、tuple 和 bool 等等
- 可变对象:对象创建后,其值可以在原地被修改,不会创建新的对象。主要有:list、dict 和 set 等
cnt = 2
print(id(cnt))
cnt += 2
print(id(cnt))
比如上面代码,cnt 前后指向的是不同的对象,输出结果如下:
140711354237896
140711354237960
python 中没有内置的常量类型,但通常约定使用 全大写 来指出应将某个变量视为常量
MAX_CONNECTIONS = 5000
列表
python 中的 list 本质上是一个动态数组,也就是可变长度的数组
- 动态数组:在内存中连续分配,通过索引能够实现随机访问,时间复杂度为
O(1) - 空间分配策略:为避免频繁的内存分配,
list在创建时会 预先分配比实际所需更多的内存空间。当元素增多并超出已分配的空间时,list会重新分配更大的内存空间,然后把原有元素复制到新空间,释放旧内存 - 补充:
tuple和listtuple是不可变序列,底层实现为静态数组,元组的元素在内存中也是连续分配的- 由于
tuple不可变,在创建时就会根据元素数量一次性分配 固定大小 的内存空间
删除 list 中的元素时,如果知道要删除元素的索引位置,可以使用 pop() 或者 del
motorcycles = ['honda', 'yamaha', 'suzuki']
# 删除 'yamaha'
del motorcycles[1]
print(motorcycles)
# 默认弹出末尾元素,可以指定索引,此处删除的是 'suzuki'
print(motorcycles.pop())
print(motorcycles)
但区别是 del 无法拿到删除的元素,pop() 可以拿到删除的元素,输出结果如下:
['honda', 'suzuki']
suzuki
['honda']
如果说我们不知道元素的索引位置,但知道我们想删除的内容,可以使用 remove()
motorcycles = ['honda', 'yamaha', 'suzuki', 'ducati']
print(motorcycles)
motorcycles.remove('ducati')
print(motorcycles)
输出结果:
['honda', 'yamaha', 'suzuki', 'ducati']
['honda', 'yamaha', 'suzuki']
remove() 和 pop() 类似,也可以返回被删除的元素,另外,方法 remove() 只删除第一个指定的值。如果要删除的值可能在列表中 出现多次,就需要使用循环来确保将每个值都删除
对于列表复制,需要使用切片,如果直接赋值,两个列表指向的会是同一个对象
players = ['charles', 'martina', 'michael', 'florence', 'eli']
# 同一个对象
players2 = players
# 副本,不同的对象
players3 = players[:]
print(id(players))
print(id(players2))
print(id(players3))
输出结果:
2011801227200
2011801227200
2011800984832
面向对象
以下面的代码为例,了解 python 中的面向对象思想
class Dog:
# 类属性
species = "Canis familiaris"
# 在 __init__ 中添加实例属性
def __init__(self, name, age):
self.name = name
self.age = age
# 动态添加实例属性
def set_age(self, age):
self.age = age
def sit(self):
print(f"{self.name} is now sitting.")
def roll_over(self):
print(f"{self.name} rolled over.")
my_dog = Dog('Willie', 6)
print(f"My dog's name is {my_dog.name}")
print(f"My dog is {my_dog.age} years old")
my_dog.sit()
my_dog.roll_over()
python 是动态类型语言,定义类时不需要像 java 那样单独把类中的属性显示写出来
在类中定义属性有两种常见方式:类属性 和 实例属性
类属性:属于类本身的属性,所有实例共享该属性,可以在类的定义中直接赋值来定义类属性,比如上面代码的
species实例属性:属于类的每个实例,通常在
__init__方法中通过self参数来定义和初始化实例属性,也可以在其他实例方法中动态添加
在 python 中,不存在像 java 那种严格意义上的私有属性(使用 private 修饰),但可以通过 单下划线前缀(弱私有约定) 来限制访问
class Person:
def __init__(self, name, age):
self._name = name
self._age = age
def _display_info(self):
print(f"Name: {self._name}, Age: {self._age}")
p = Person("Alice", 25)
# 可以访问,但不建议
print(p._name)
p._display_info()
在上述代码中,_name、_age 和 _display_info 以单下划线开头,按照约定应在类内部使用,但仍然可以在类外部访问它们 。因此这仅仅是一种约定,而非强制性的修饰符
类的继承
# 父类
class Car:
def __init__(self, make, model, year):
self.make = make
self.model = model
self.year = year
self.odometer_reading = 0
def get_descriptive_name(self):
long_name = f"{self.year} {self.make} {self.model}"
return long_name.title()
def read_odometer(self):
print(f"This car has {self.odometer_reading} miles on it.")
def update_odometer(self, mileage):
if mileage >= self.odometer_reading:
self.odometer_reading += mileage
else:
print("You can't roll back odometer!")
def increment_odometer(self, miles):
self.odometer_reading += miles
# 子类
class ElectricCar(Car):
def __init__(self, make, model, year):
super().__init__(make, model, year)
my_tesla = ElectricCar('tesla', 'models', 2019)
创建子类时,父类 必须包含 在当前文件中,且位于子类前面。这里的 必须包含 不是说父类与子类必须写在同一个 .py 文件中,我们也可以把父类和子类分别写在不同的 .py 文件里,比如下面的代码:
# animal.py
class Animal:
def __init__(self, name):
self.name = name
def speak(self):
print(f"{self.name} makes a sound.")
# dog.py
from animal import Animal
class Dog(Animal):
def speak(self):
print(f"{self.name} barks.")
# 创建子类实例并调用方法
dog = Dog("Buddy")
dog.speak()
运行 dog.py 时,python 会先从 animal.py 文件里导入 Animal 类,然后创建 Dog 类的实例并调用其方法
重写父类方法
父类方法不符合子类模拟的实物行为时,都可以进行重写。为此,可在子类中定义一个与要重写的父类方法同名的方法,这样,python 将不考虑父类方法,只关注子类方法
算法相关
如何遍历可迭代对象?
以 https://leetcode.cn/problems/two-sum/description/ 为例
使用
range函数,其中使用到range去创建一个可迭代对象(对象中数字从 0 开始)range的完整语法:range(start, stop[, step]),其中:start:可选参数,序列起始值,默认为 0stop:必选参数,序列结束值,生成的序列不包含该值step:可选参数,序列步长,默认是 1
class Solution: def twoSum(self, nums: List[int], target: int) -> List[int]: for i in range(len(nums)): for j in range(i + 1, len(nums)): if nums[i] + nums[j] == target: return [i, j] return []使用
enumerate函数,遍历可迭代对象时同时获取元素的索引和值enumerate的完整语法:enumerate(iterable, start=0),其中:iterable:必选参数,代表要遍历的可迭代对象start:可选参数,用于指定索引的起始值,默认是 0
class Solution: def twoSum(self, nums: List[int], target: int) -> List[int]: indices = {} for i, v in enumerate(nums): pre = target - v if pre in indices: return [i, indices[pre]] indices[v] = i return []
这里提到 range 函数生成可迭代对象,该对象不是 list 也不是 tuple,而是 range 类型
range 对象是可迭代的,所以可以用于 for 循环
for i in range(5): print(i)内存高效:range 对象不会像 list 那样一次性把所有元素存储在内存中,而是在迭代时逐个生成元素,因此在处理大序列时,能节省大量内存
不可变:一旦 range 对象被创建,其元素和范围就不能改变。若要得到不同的范围,需要重新创建一个新的 range 对象
文件与异常
文件
with open('test.txt') as file_object:
contents = file_object.read()
print(contents)
上面的代码里,open() 函数打开对应文件,返回一个表示文件 test.txt 的对象,python 将该对象赋给 file_object 供以后使用
关键字 with 在不再需要访问文件后将其关闭,我们也可以调用 open() 和 close() 来打开和关闭文件,但这样做时,如果程序存在 bug 导致 close() 未执行,文件将不会关闭,可能导致数据丢失或受损
tips:如果文件的绝对路径比较长,可以把它赋给一个变量,再把变量传递给 open()
异常
类似 java,当发生让 python 不知所措的错误时,它都会创建一个异常对象。如果程序中有处理该异常的代码,程序将继续运行;如果未对异常进行处理,程序将停止并显示 traceback,其中包含有关异常的报告
写代码时如果认为可能发生错误,可编写一个 try-except 代码块来处理可能引发的异常。如果 try 代码块中的代码引发了异常,python 将查找与之匹配的 except 代码块并运行其中的代码
# 程序停止,显示 traceback
print(1 / 0)
# 程序继续执行,异常被捕获并运行 except 代码块中的代码
try:
print(1 / 0)
except ZeroDivisionError:
print("You can't divide by zero")
静默失败
每次捕获到异常时,可能不需要告诉用户,想让程序保持静默,这里就可以使用 pass 语句
def count_words(filename):
# 计算一个文件大致包含多少个单词
try:
--snip--
except FileNotFoundError:
pass
else:
--snip
filenames = {'1', '2', '3', '4'}
for filename in filenames:
count_words(filename)
假设文件 “3” 不存在,python 在执行上述代码时,只会打印 1、2、4 的单词数,不会有任何 traceback
Django
Django 是一个高级的 Python Web 框架,采用了模型-视图-控制器(MVC)的架构模式,能够快速、高效地构建 Web 应用程序。
在 PyCharm 中创建一个 Django 项目,PyCharm 会自动构建项目需要的虚拟环境,下面是完成创建的目录结构。
目录 learning_log 包含 5 个文件,最重要的是 settings.py、urls.py 和 wsgi.py。
- settings.py:指定 Django 如何与系统交互以及如何管理项目,可以根据具体需求,选择修改一些设置并添加一些设置
- urls.py:该文件告诉 Django 应该创建哪些页面来响应浏览器请求
- wsgi.py:wsgi 是 Web Server Gateway Interface 的缩写,在 Django 项目中,
wsgi.py文件是启动 WSGI 服务器的入口文件,它负责创建一个 WSGI 应用程序对象,加载 Django 项目的配置(设置DJANGO_SETTINGS_MODULE环境变量指定配置文件 ),并将应用程序对象传递给 WSGI 服务器,使服务器能处理传入的 HTTP 请求 - asgi.py(补充):asgi 是 Asynchronous Server Gateway Interface 的缩写,是异步服务器网关接口,是对 wsgi 的扩展,用于处理异步 Web 请求,能更好地支持异步编程和 WebSocket 等长连接操作
创建数据库
首先创建一个供 Django 使用的数据库,在终端执行下面的指令:
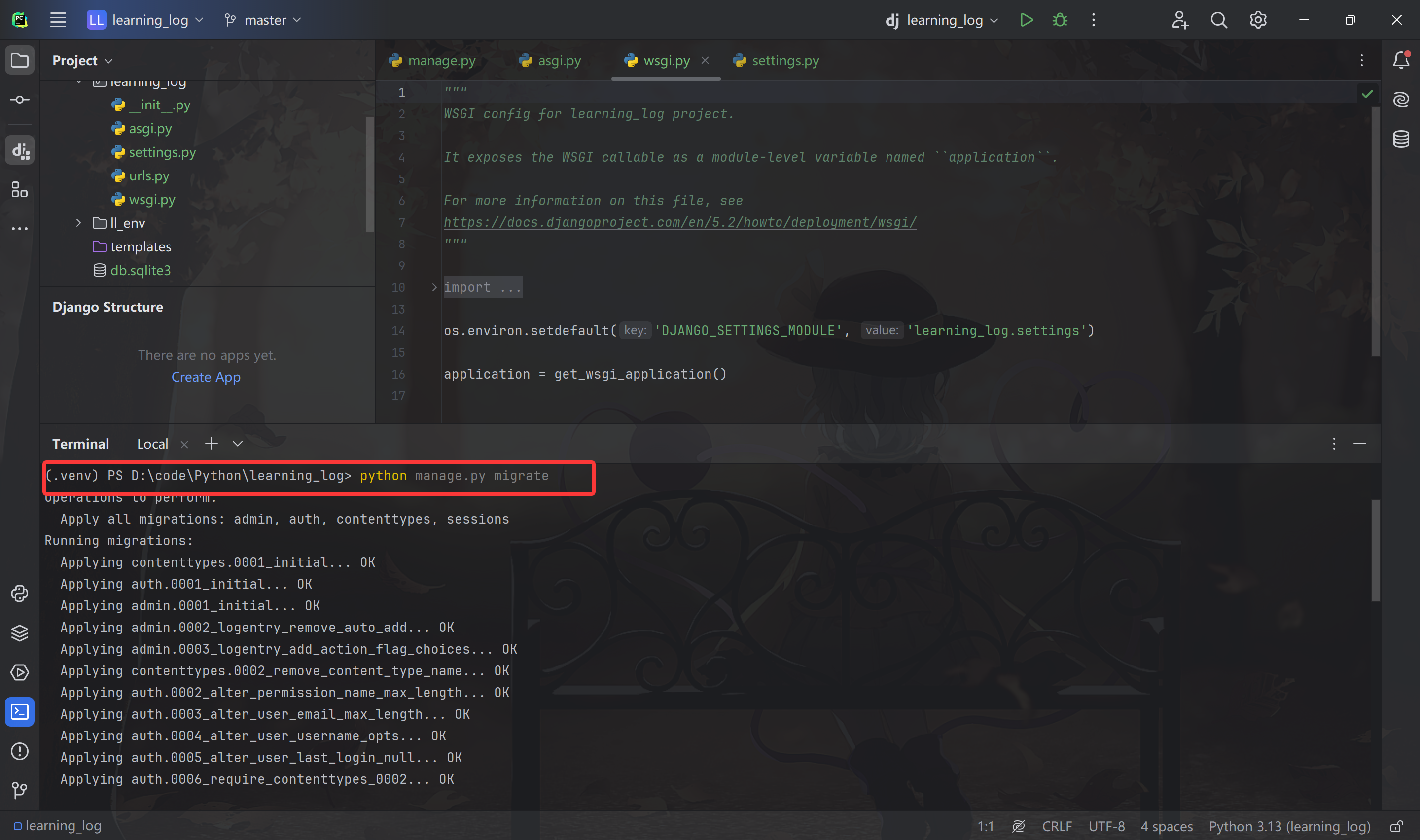
我们将修改数据库成为 迁移 数据库,首次执行 migrate 命令时,将让 Django 确保数据库与项目的当前状态匹配。在使用 SQLite 的新项目中首次执行这个命令时,Django 将新建一个数据库。SQLite 是一种使用单个文件的数据库,不用太关注数据库管理的问题。
查看项目
可以使用 runserver 查看项目的状态:
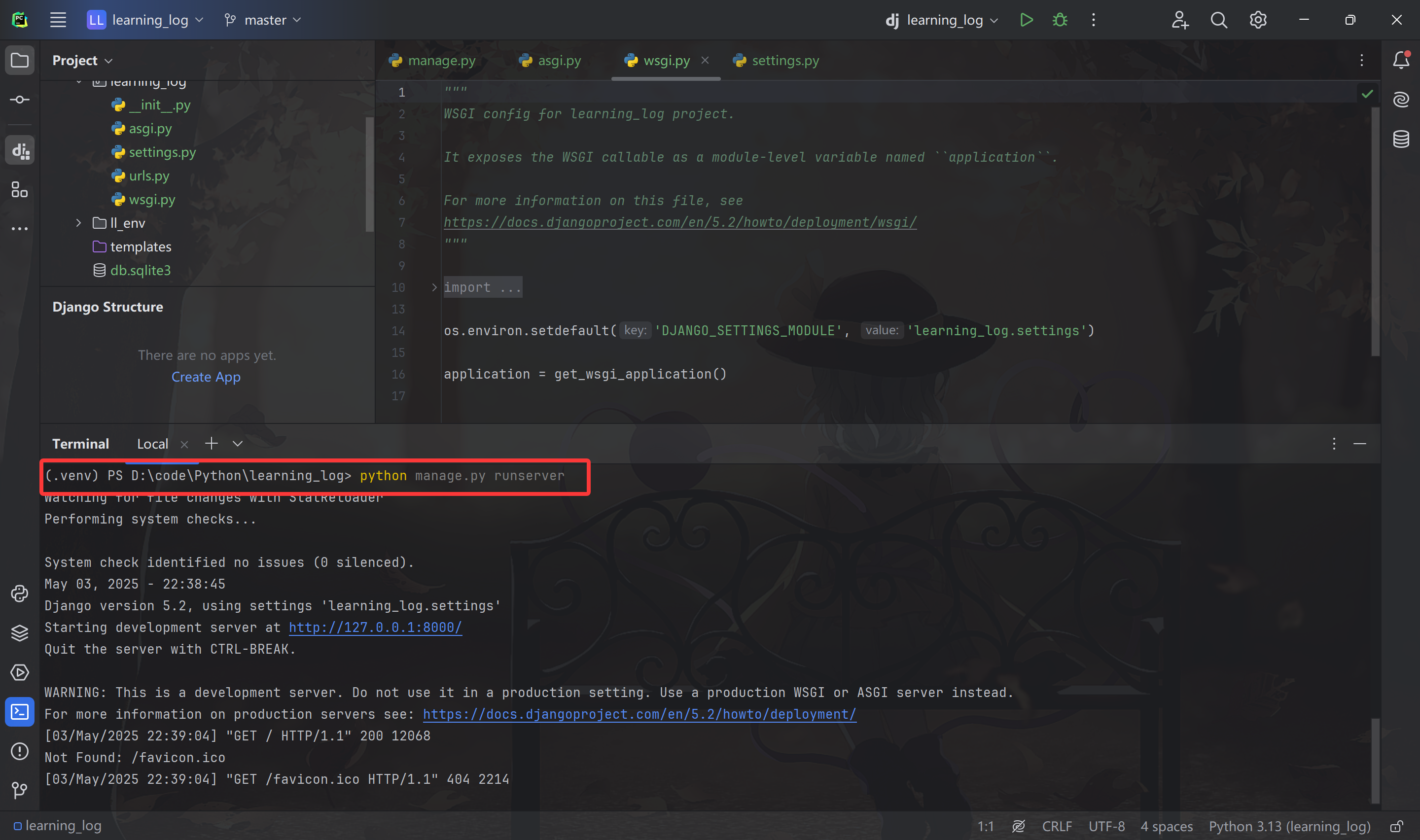
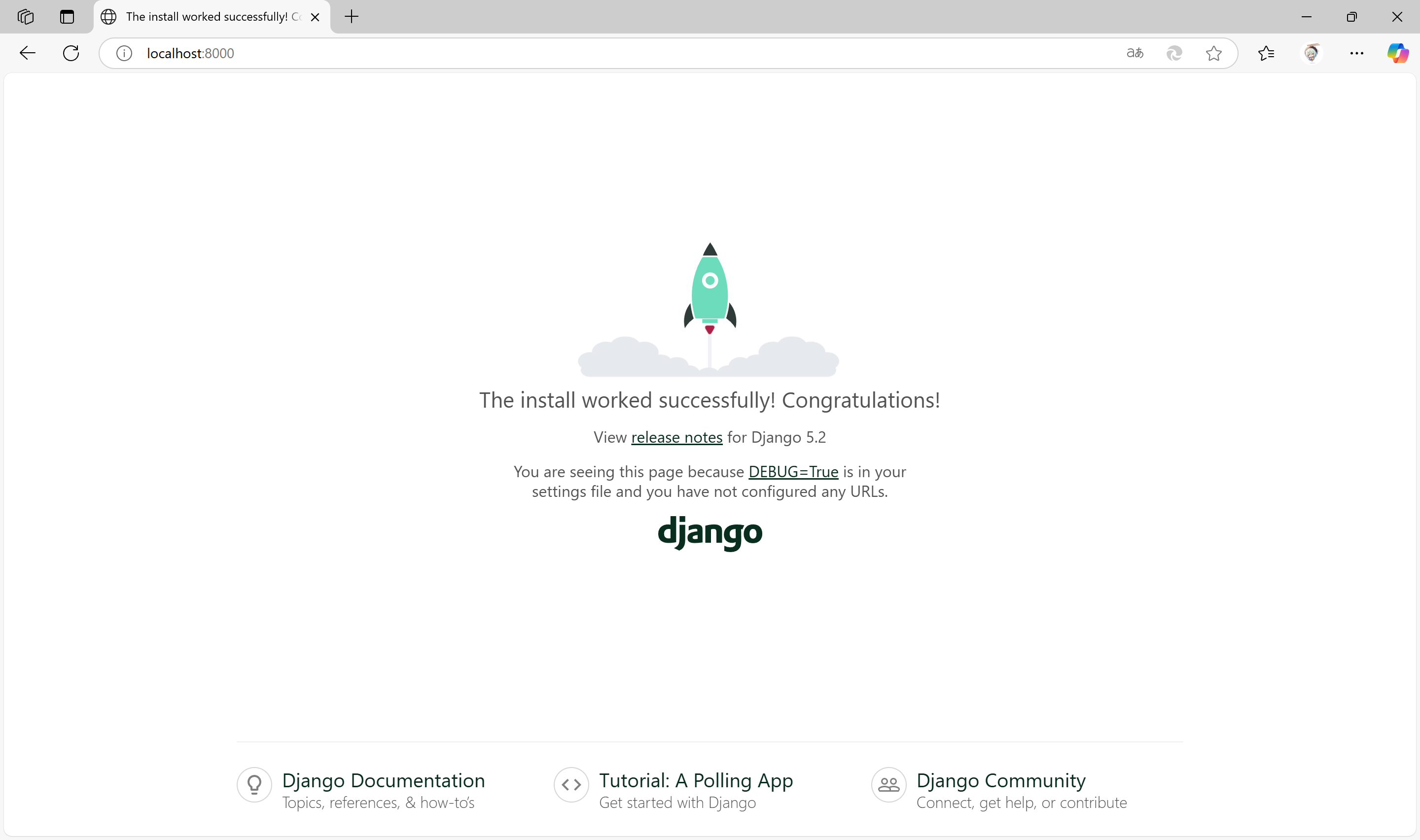
Django 启动了一个名为 development server 的服务器,此时使用浏览器访问 http://localhost:8000/ 以请求页面,Django 服务器将进行相应,生成合适的页面并发送给浏览器,如下图:
应用程序
在 Django 中,应用程序(app)是一个具备独立功能的模块,类似于 java spring 框架的 module。
每个 Django 应用程序专注于一个特定的功能领域,比如博客项目可以有一个 “文章” 应用程序,专门负责文章的创建、编辑、展示和删除操作;还可以有一个 “评论” 应用程序,用于处理用户对文章的评论功能
一个新创建的应用程序如下图
应用程序中各个 .py 文件的作用:
__init__.py:Python 中用于标识该目录是一个 Python 包,早期可用于导入包时执行初始化代码,现在空文件也能让目录成为包,方便模块组织和管理admin.py:用于注册模型到 Django 自带的后台管理系统,注册后可在后台对相应模型数据进行增删改查等操作 ,方便管理网站数据apps.py:定义应用程序的配置类(AppConfig),可配置应用元数据和行为,如设置应用名称、标签;重写ready()方法可执行启动初始化操作,像信号注册models.py:定义数据模型,即映射数据库表结构,每个模型类对应数据库一张表,类中的字段对应表中的列,通过它可进行数据库交互,实现数据存储、查询、修改、删除等操作tests.py:编写测试代码的地方,用于对应用程序功能进行自动化测试,确保应用按预期工作,提高代码稳定性和可靠性,比如测试视图逻辑、模型方法等是否正确views.py:处理业务逻辑,接收用户请求,根据请求进行数据处理(可能涉及调用模型获取数据),然后选择合适模板渲染并返回响应给用户
定义模型
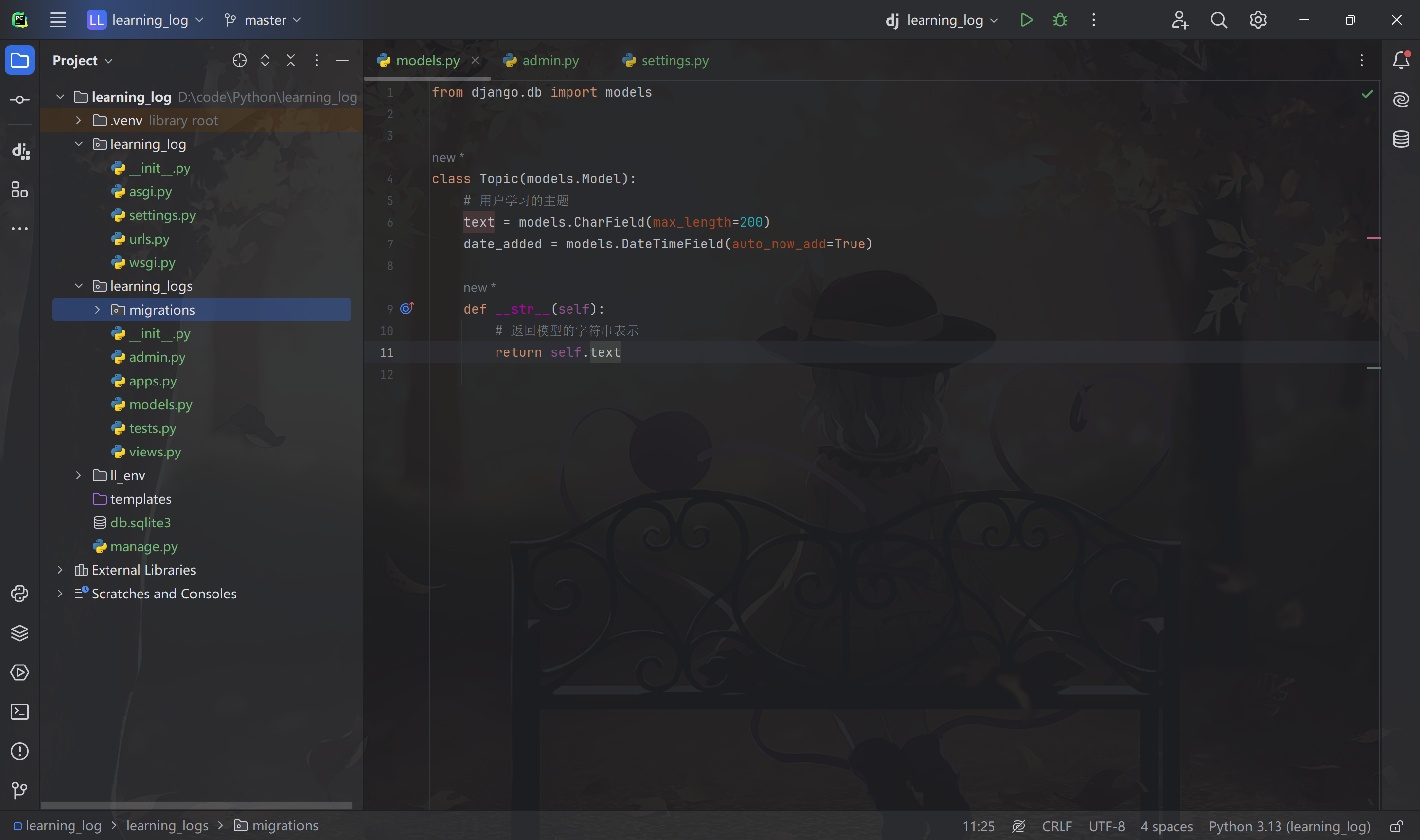
此处定义了一个 Topic 类,继承 Model,在该类中添加了两个属性:text 和 date_added,表示用户在学习笔记中创建的主题。
属性 text 是一个 CharField —— 由字符组成的数据,属性 date_added 是一个 DateTimeField —— 记录日期和时间的数据。
激活模型
要使用模型,必须让 Django 将上面的应用程序包含到项目中,这里就需要修改 settings.py 文件,其中有个片段告诉 Django 哪些应用程序被安装到了项目中并将协同工作,在里面添加自己的应用程序即可。
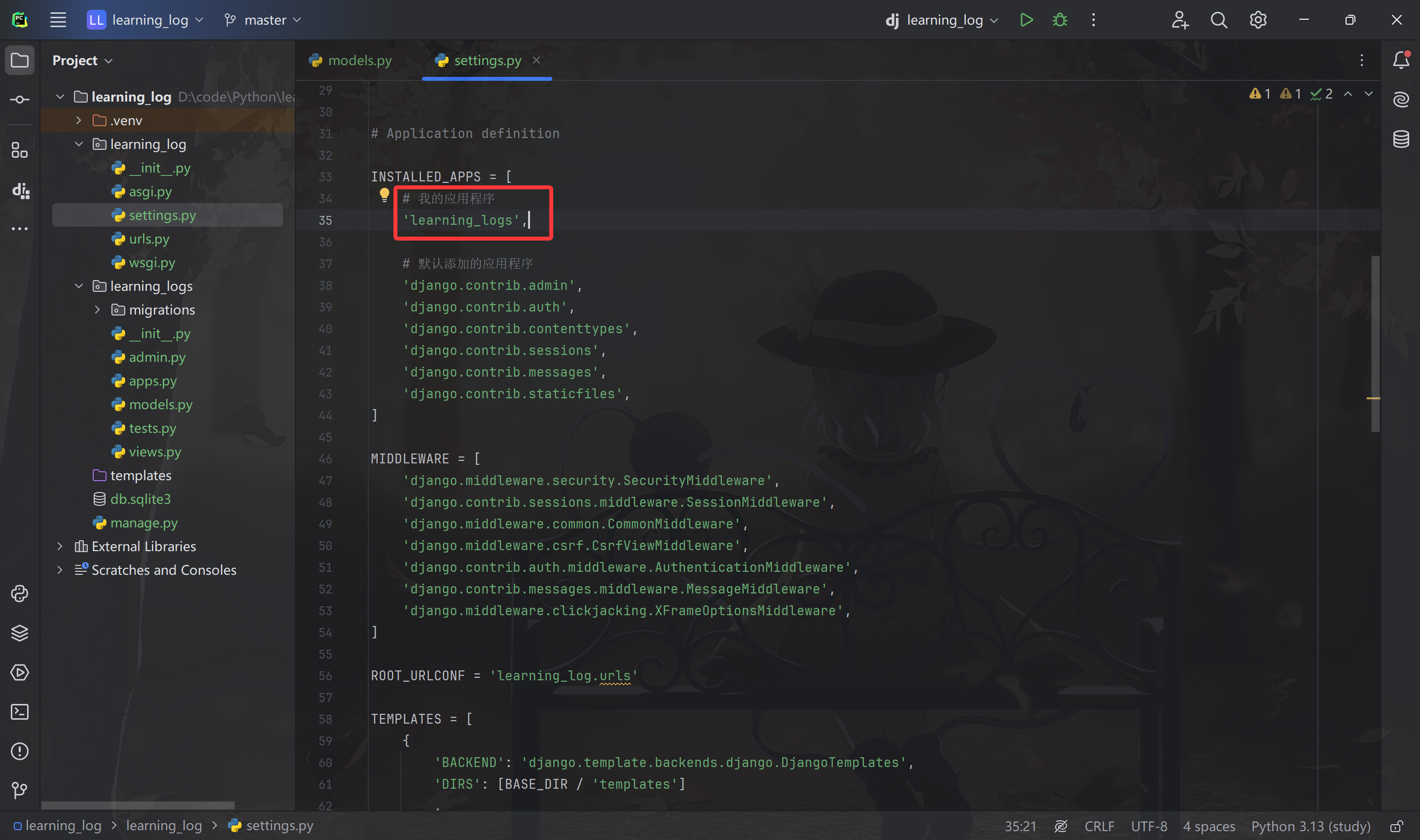
注意,这里务必将自己创建的应用程序放到默认应用程序前面,这样能够覆盖默认应用程序的行为。
接下来,需要让 Django 修改数据库,使其能够存储与模型 Topic 相关的信息,为此,在终端窗口中执行下面的命令:

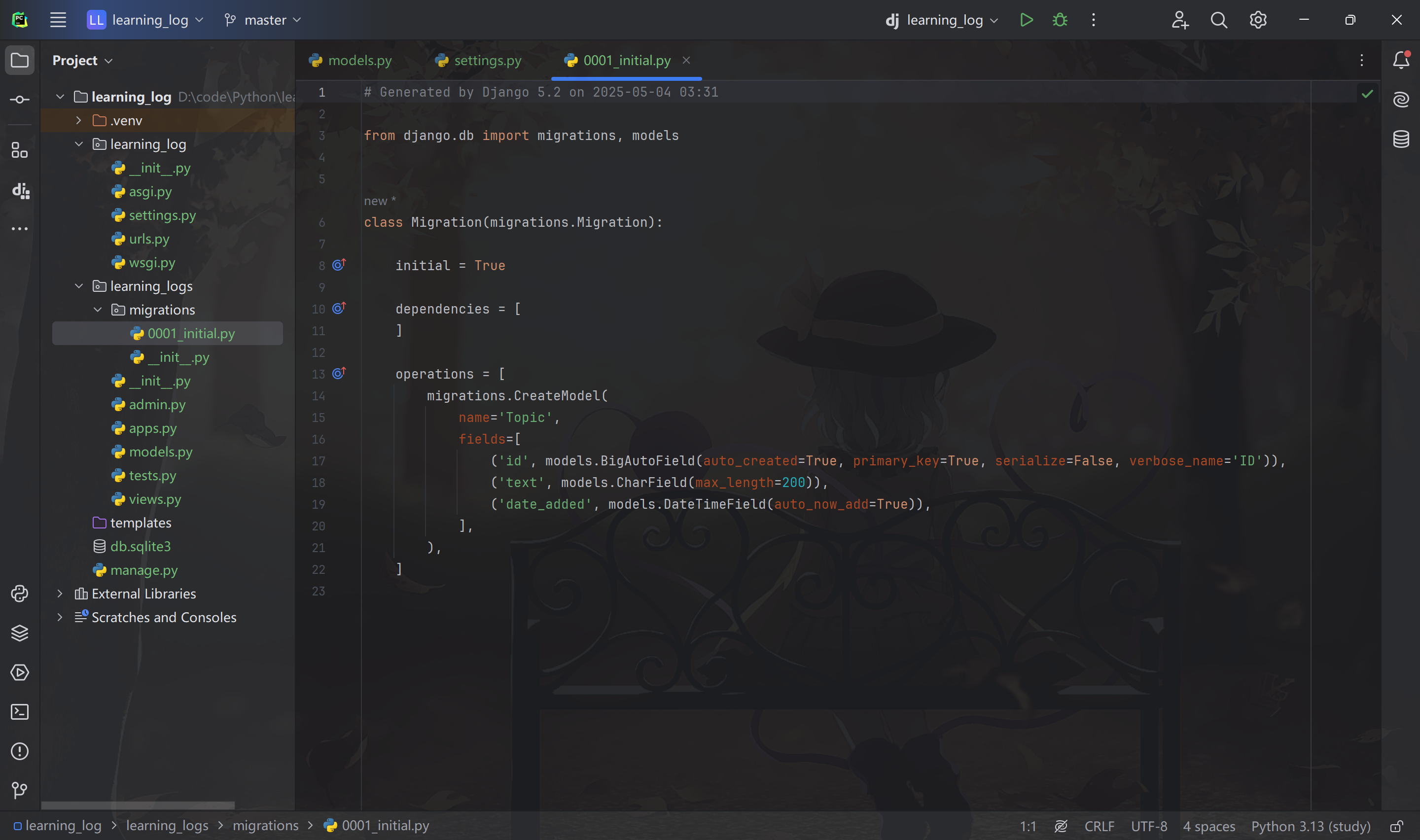
输出表明 Django 创建了一个名为 0001_initial.py 的迁移文件,这个文件将在数据库中为模型 Topic 创建一个表。
补充:Django 中的 迁移 是管理数据库结构变化的一种机制,用于在开发过程中修改模型(Model)并同步数据库的变化。当对 Django 模型进行更改时,迁移会记录这些变化,每次修改后运行 python manage.py makemigrations 命令,Django 会生成迁移文件,该文件记录了从一个数据库状态到另一个状态需要执行的操作,比如下图中的 0001_initial.py 迁移文件:
下面应用这种迁移,让 Django 替我们修改数据库:
每当需要修改 “学习笔记” 管理的数据时,都采取如下三个步骤:修改 models.py,对 learning_logs 调用 makemigrations,以及让 Django 迁移项目