参考:https://golangguide.top/
对于 MySQL 数据库,为了得到更高的性能,一般会搭建 MySQL 集群实现读写分离,主库用于写操作,从库用于读操作。虽然主库一般用于写,但也是能读的。那么就有这样一个问题:在 MySQL 集群中,在从库已经读到了最新值的情况下,主库还有可能读到旧值吗?
正常的主从更新流程
假设在主库和从库中都有一张 user 表,此时有以下数据:
| id | name | age |
|---|---|---|
| 1 | 小王 | 72 |
| 2 | 小李 | 60 |
我们往主库执行写操作时,一般都能理解成单条语句的事务,比如下面两段 SQL 效果相同:
update user set age = 50 where id = 1;
begin;
update user set age = 50 where id = 1;
commit;
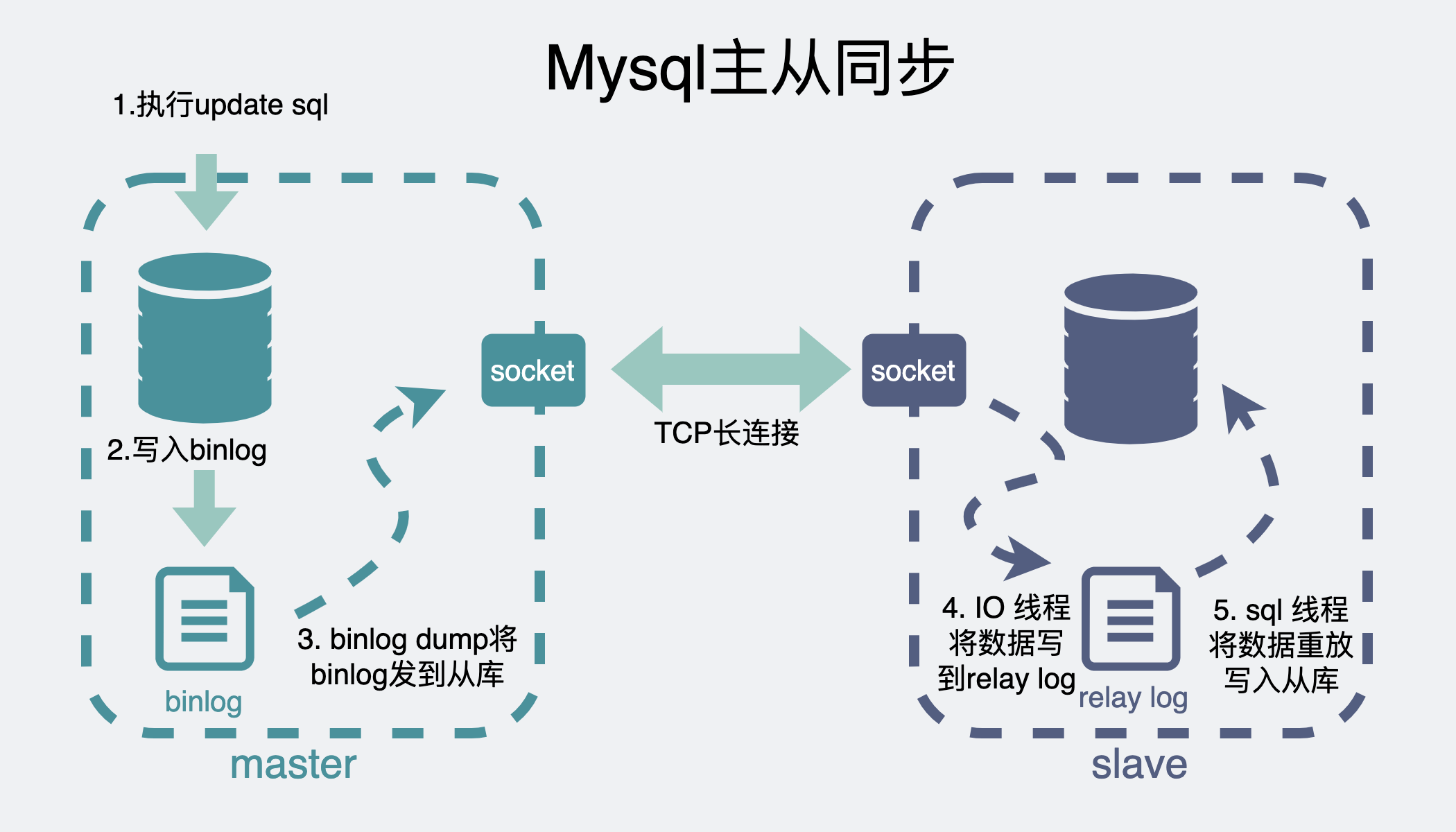
如果事务执行成功了,数据会先写入到主库的 binlog 文件中,然后再刷入磁盘。
binlog 文件是 MySQL 的 server 层日志,记录了用户对数据库有哪些变更操作,比如建数据库表、加字段,以及对某些行的增删改等。
如果两个 MySQL 节点配置好了主从关系,那么它们之间会建立一个 TCP 长连接,主要用于传输同步数据。
除此之外,主库还会再创建一个 binlog dump 线程,将 binlog 文件的变更发送给从库。以上,主库的工作就结束了。
当从库通过之前创建的 TCP 长连接收到 binlog 后,会有一个 IO 线程负责把收到的数据写入到 **relay log(中继日志)**中,然后再有一个 SQL 线程来读取 relay log 的内容,接下来对从库执行 SQL 语句操作,完成数据的主从同步。
为什么要先写一遍 relay log 然后再写从库?
relay log 的作用就类似一个中间层,主库是多线程并发写的,从库的 SQL 线程是单线程串行执行的,所以两边的生产和消费速度肯定不同。当主库的 binlog 消息过多时,从库的 relay log 可以起到暂存主库数据的作用,接着从库的 SQL 线程再慢慢消费这些 relay log 数据,这样既不会限制主库发消息的速度,也不会给从库造成过大的压力。
因此总结起来,主从同步的步骤如下:
- 执行更新 SQL 语句
- 主库写成功时,更新 binlog
- 主库 binlog dump 线程将 binlog 的更新部分发给从库
- 从库 IO 线程收到 binlog 更新部分,写入到 relay log 中
- 从库 SQL 线程读取 relay log 内容,重放执行 SQL,最后主从一致
主库更新后,从库都读到最新值了,主库还有可能读到旧值吗?
答案是会的,这里需要先了解 MySQL 的四种隔离级别,分别是:读未提交(Read uncommitted),读已提交(Read committed),可重复读(Repeatable read)和串行化(Serializable)。在不同的隔离级别下,并发读写效果是不一样的。
四种隔离级具体可以看这篇:https://yuk1pedia.github.io/2024/11/MySQL-Principles/
掌握了 MySQL 的四种隔离级别后,就可以回到这个问题:主库更新后,从库都读到最新值了,主库还有可能读到旧值吗?
我们还是以这张表为例:
| id | name | age |
|---|---|---|
| 1 | 小王 | 72 |
| 2 | 小李 | 60 |
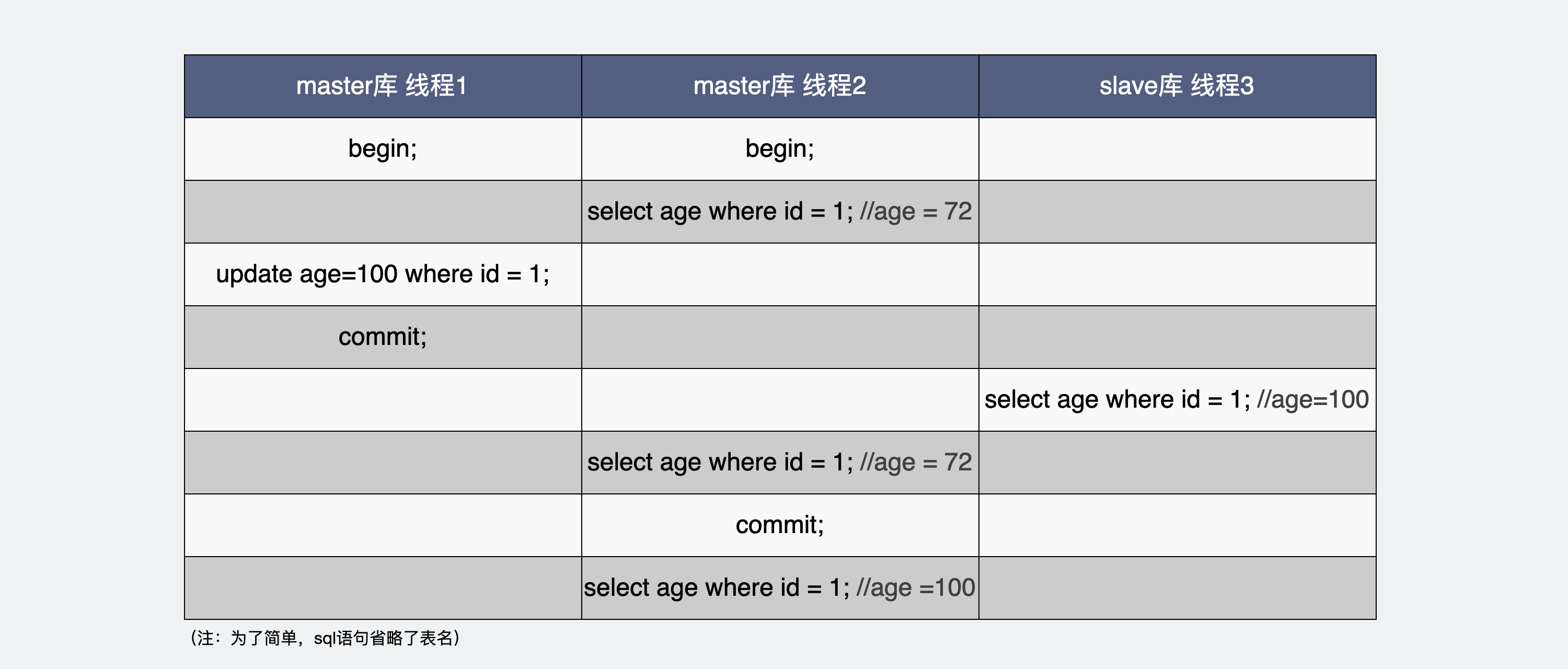
假设当前数据库事务的隔离级别是可重复读,主库中有 A、B 两个线程,同时执行 begin 开启事务,此时主库的线程 2 先读一次 id = 1 的数据,发现 age = 72,由于当前事务隔离级别是可重复读,那么只要线程 2 在它提交之前不做任何更新操作,不管重复读多少次,age 都是 72。
在这之后主库的线程 1 将 age 更新为 100,且执行 commit 提交了事务,那么主库线程 1 就会产生 binlog,然后同步给从库,此时从库去查询就能查到 age = 100。
回过头来,此时主库中的线程 2 还没有提交事务,所以就会一直读到旧值 age = 72。当线程 2 提交了事务,再查询就能查到最新的数据 age = 100了。
从结论上来说,出现了从库都读到最新值了,主库却读到了旧值的情况。